
Preview to The Future of Power Podcast Episode 2: Unblocking AI’s Growth with Fault Managed Power
In the most recent episode of VoltServer’s The Future of Power podcast, Steve Eaves and I spoke with Mike Starego (Principal Electrical Engineer at Southland Industries) about why designing power distribution is becoming what designers call a “wicked-hard” problem because design requirements are changing so quickly. The central cause is the rapidly increasing peak power demands for AI server racks.
So I asked, “Why are servers so densely packed in AI data centers? Why can’t we just solve the problem by spreading everything out more?” Steve and Mike explained that it’s all about reducing latency. The physics behind latency sparked another interesting discussion thread about how those same physical limits are making the vertical space above servers increasingly valuable in ways many people don’t yet realize.
After the recording, I did some more research to better understand their point.
How Latency Adds Up AI
AI workloads, like training large language models, need dozens or even hundreds of GPUs working simultaneously on different parts of the same job because otherwise, it would take years to finish. During this process, GPUs must exchange information with each other hundreds of thousands of times. Even tiny increases in latency during these exchanges can stack up into major delays, driving up costs (because there is a high cost per hour to use GPUs) and ultimately degrading the end-user experience.
Communication Fabrics and Latency
What I hadn’t fully appreciated before is just how critical it is to pack as many GPUs as possible into the same chassis and then the same server rack to keep latency low. What’s even more interesting, from a systems thinking perspective, is the complexity of managing all the trade-offs this creates.
There’s a clear hierarchy of communication fabrics inside a data center:
- Within the server
- Between servers inside the same rack
- Between servers across different racks
Network Architecture and Why Racks Are Getting Denser
Latency is driven by the communication system GPUs use to talk to each other, called a fabric. The fabric that can be used depends on where the GPUs are located relative to one another.
- The fastest fabric is within the same server, where GPUs communicate over a local NVSwitch fabric.
- The next fastest, but roughly 300X slower, is between GPUs in different servers inside the same rack, using InfiniBand or Ethernet fabrics.
- The slowest—roughly 6000X slower than within-server communication (or about 20X slower than between-server)—is communication between GPUs in different racks across the data center fabric.
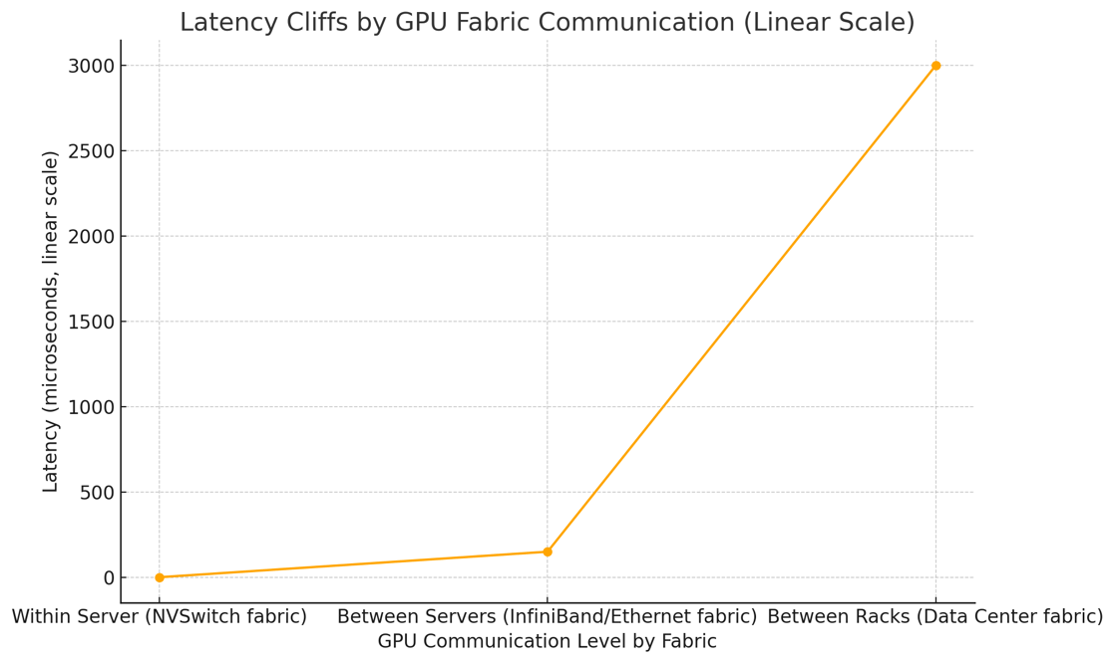
Given that a job may require hundreds of thousands of exchanges between GPUs, engineers work extremely hard to cram as many GPUs as possible within the same server and then within the same rack. But since today’s GPUs can have a peak power demand of up to 1200W, this results in extremely high-power densities.
The Vertical Space Question
What’s critical to understand is that even if just 1% of the communication crosses racks, that tiny fraction can dominate the total system runtime. This is because the slowest operation sets the pace of the entire workload. Like runners in a relay race, all the operations at each step must wait for the slowest data transfers to complete before moving to the next stage. In practice, this means that even minimal cross-rack traffic can drag down system-wide efficiency by orders of magnitude, turning an extremely expensive, high-performance cluster into an underutilized, power-hungry bottleneck.
That’s why system designers aggressively optimize locality: the closer the GPUs, the faster and more efficient the job.
Clearly, there is a powerful incentive to increase the number of servers in a rack and, thus, the height of the racks. That’s probably already showing up in the industry, with vendors and analysts reporting that taller racks are one of the fast-growing segments.
However, physical costs push back against the value of reducing latency. In the episode, Mike Starego went into detail about how traditional power distribution methods require adding lots of space-hungry equipment like more floor PDUs and additional overhead busways in order to deliver that extra power. This reduces not only the available floor space for racks but also the vertical space needed for the extra cooling mechanisms and cabling required as power densities increase. That’s what makes it such a wicked-hard problem.
Latency Value Curve vs Physical Cost Curve
Ultimately, whichever force dominates – the latency value curve or the physical cost curve – will determine if racks will continue to grow taller. But historically, we’ve seen that competition in rapidly emerging markets usually makes the value curve grow faster than the cost curve. For instance, in the early days of the high-frequency trading market, early adopters spent enormous amounts of money on physical costs to gain tiny advantages in latency. In 2010, Spread Networks spent $300 million to cut trading latency by 3 milliseconds.
In turn, those high levels of willingness to spend incentivize competition across equipment and software manufacturers to invest in innovations that bend down the physical cost curve.
How Fault Managed Power (FMP) Fits In
In the episode, we discussed how Fault Managed Power (FMP) is one of those innovations. For instance, it allows operators to deliver massive amounts of power to individual racks without needing to add more floor PDUs. Moreover, FMP dramatically reduces the amount of vertical space required for power and data cabling. Overall, the upcoming generation of FMP technology will reduce the volume of space required for equipment by around 80%.
From a product evolution perspective, traditional AC systems are largely made up of human labor, copper, and steel – meaning their costs generally increase over time as material and labor prices rise. In contrast, FMP systems are built on a technology layer, which means their benefits can rapidly accelerate while system costs decline over time, following a technology-driven cost curve similar to other innovation-driven sectors.
The Option Value Advantage
We closed the episode by discussing FMP’s unique ability to efficiently manage vertical space. Since it doesn’t use conduit or busways, it takes up only a fraction of the space. It’s also much easier to move and change.
In financial terms, this creates enormous option value for data center operators who want to maximize their capacity to respond to rapid and unpredictable changes in chip technology. For example, Mike mentioned how one of their customers is designing for 200 kW racks – not because they need that much density today, but because they want to build in enough flexibility to handle whatever rack densities look like two years from now when the data center goes live.
In that case, if the data center eventually ends up undershooting future rack densities, they’ll be much better off if they’ve left extra space above the racks – giving themselves room to add more cooling, more cabling, and, critically, more power distribution – than if they had packed everything too tightly up front.
The episode is scheduled to be released in early June.